如何批量去除Excel中的公式保留值?推荐三种常用方法
很多表格中会嵌入大量公式,直接复制、分享或打印时,容易出现公式报错、数值变动,手动逐单元格去除公式又耗时费力。本文将结合实际的工作场景,后续将为大家推荐三种常用高效方法,轻松实现批量去除Excel公式、保留原始数值,摆脱手动操作的繁琐,提升办公效率。
财务岗核对账目、汇总报表时,表格中布满求和、对账公式,分享给其他同事核对时,不小心修改单元格就会导致公式报错、数值错乱,手动逐格复制粘贴数值去除公式,几十上百个单元格就要耗很久。
行政岗整理考勤、工资台账,公式计算出的结果需要固定保留,避免后续误操作导致数值变动,手动处理不仅繁琐,还可能误删关键数据。批量去除公式保留值,既能保证数据稳定,又能提升表格打开和编辑速度,避免不必要的麻烦。本文分享了三种高效方法,不管单个文件还是多个Excel文件都可以轻松清除Excel中的公式。
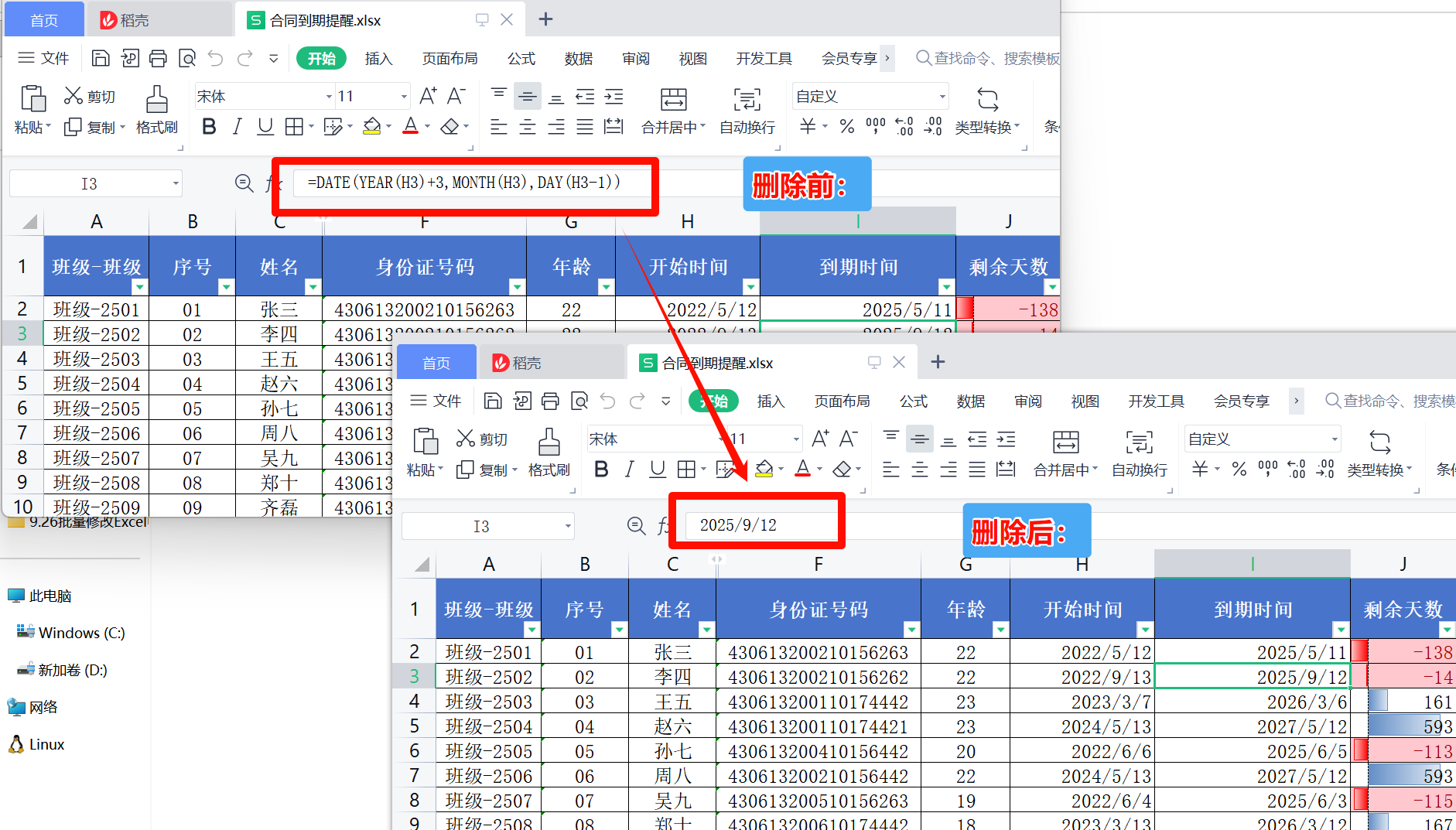
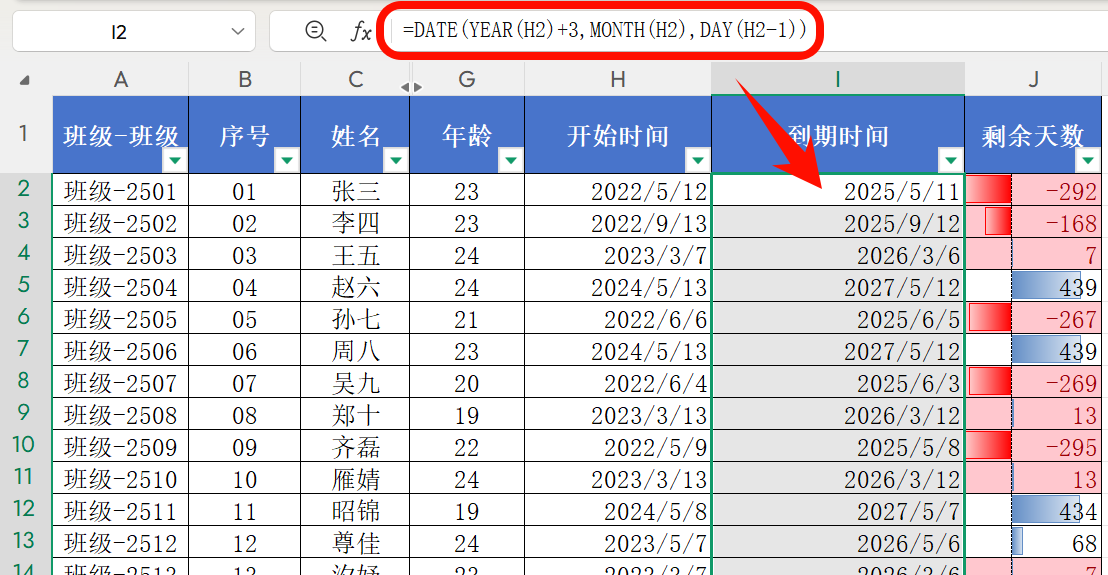
去除Excel公式效果预览
方法一:借助【鹰迅批量处理工具箱】处理
优势:可以同时批量处理多个Excel文件,不需要一个个打开文件。
不足:需要额外下载电脑端软件。
操作步骤:
第一步、打开「鹰迅批量处理工具箱」,选择「Excel工具」,右侧在文件内容分类中选择「删除 Excel 公式」的功能。
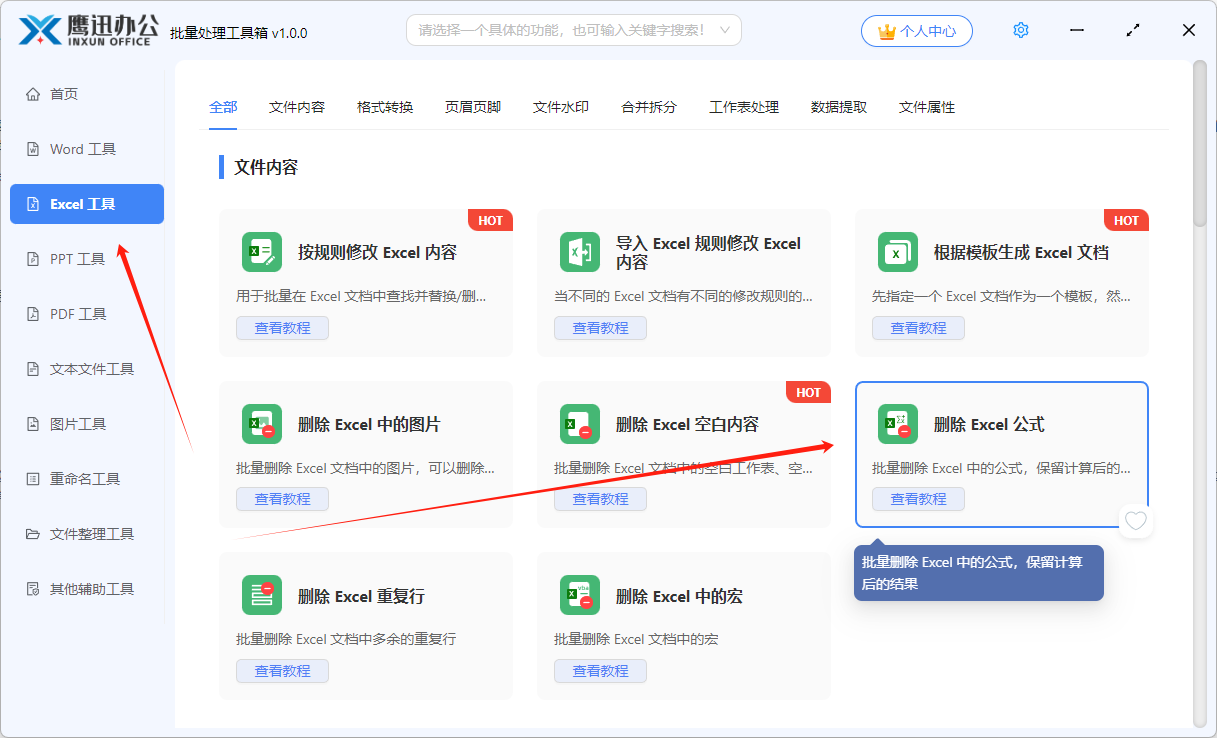
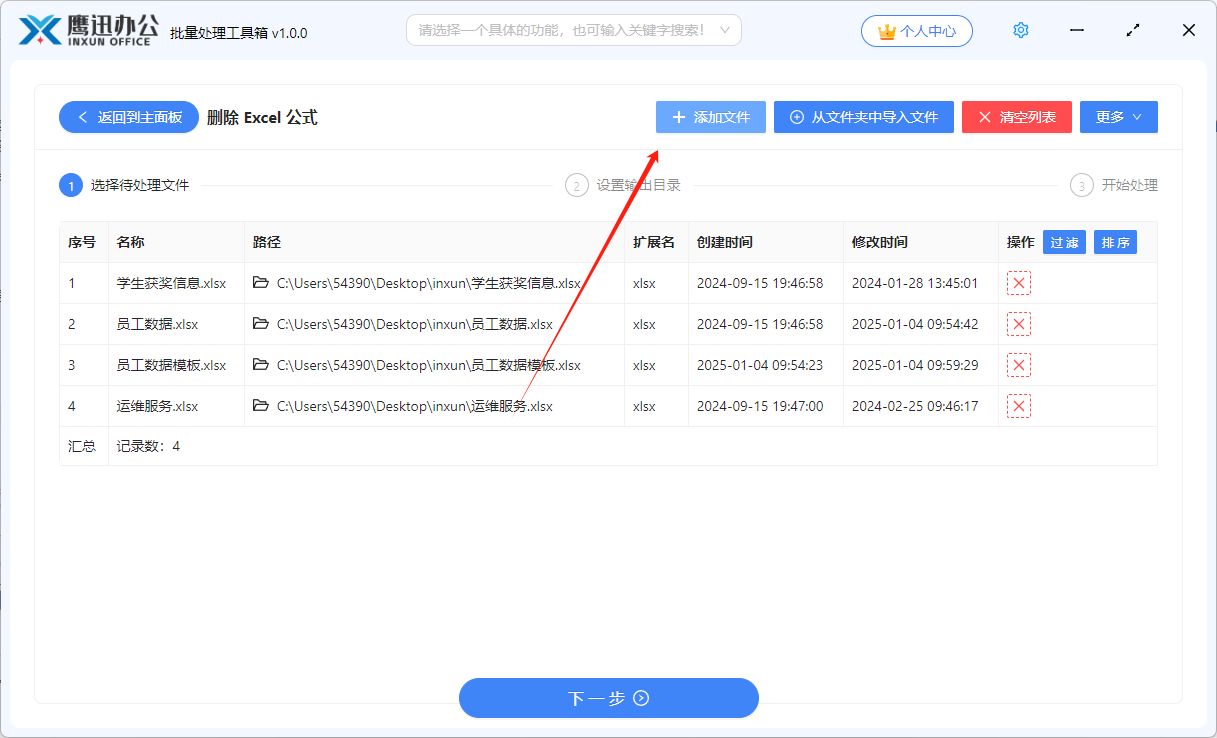
第二步、选择需要删除公式的 Excel 文档,可以是多个文档。
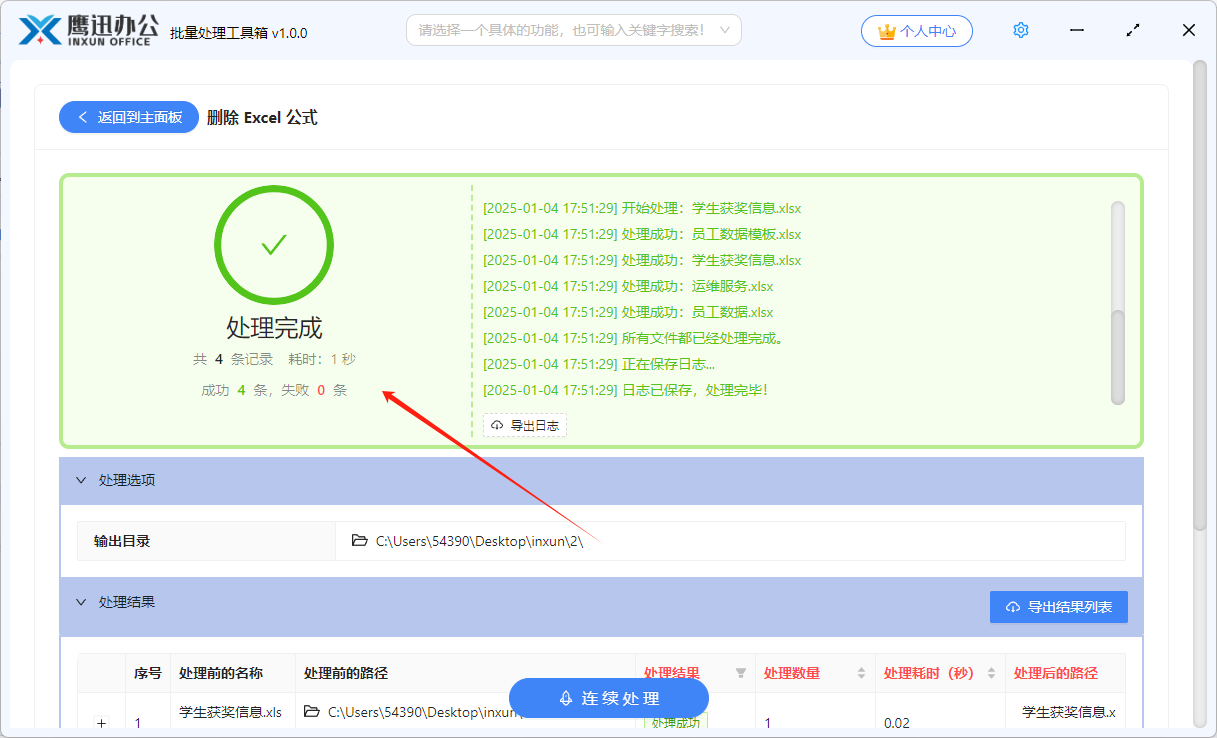
第四步、处理完成。
方法二:利用自带功能处理
优势:不需要下载软件,单个表格处理很方便。
不足:只方便处理少量文件和区域。
操作步骤:
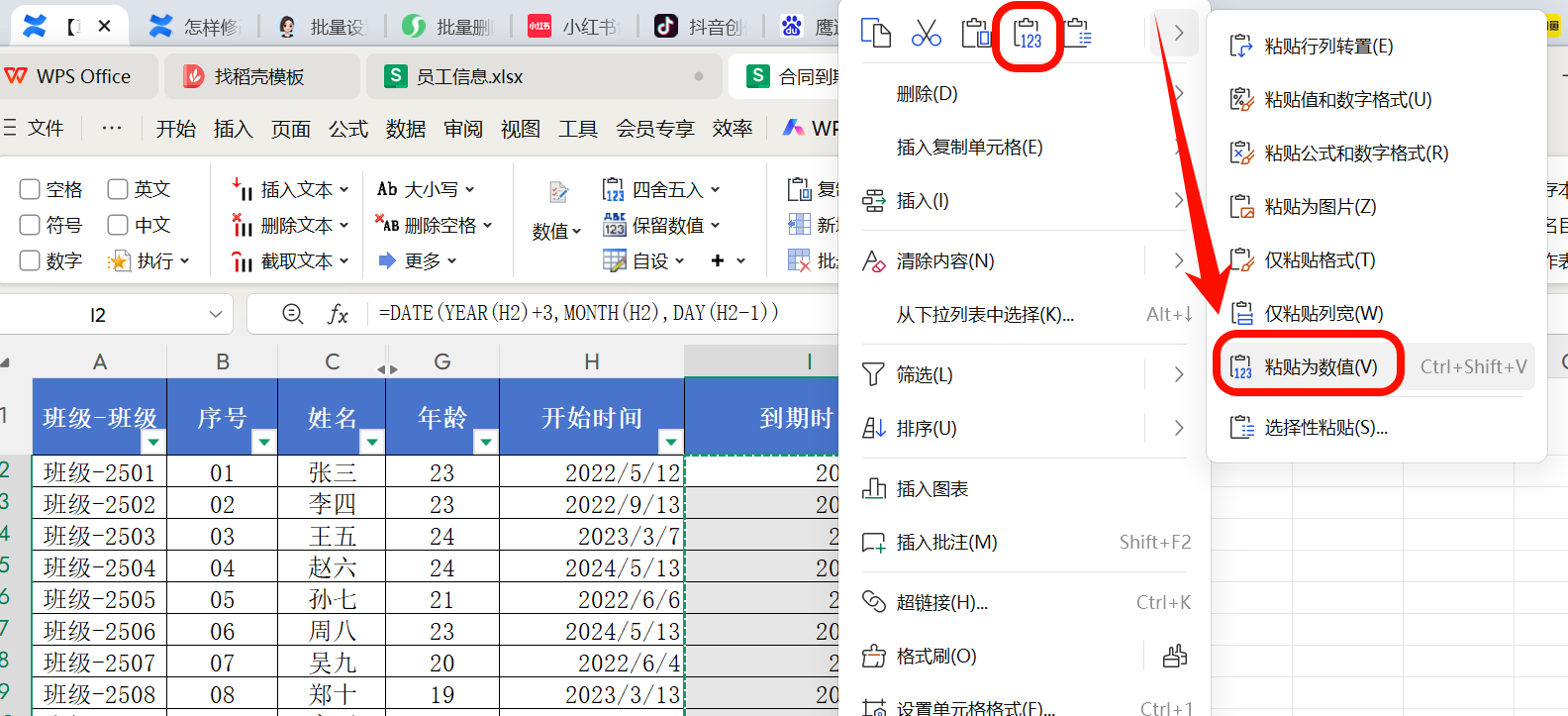
1、Ctrl+A键,全选整个需要删除公式,只保留计算后的值的单元格区域。
2、复制选中区域,进行选择性粘贴-粘贴为数值。
方法三:使用openpyxl库,借助Python代码来实现
优势:不需要下载软件,可以处理多个文件。
不足:专业要求高。
操作步骤:
import os
import glob
from openpyxl import load_workbook
from openpyxl.utils import get_column_letter
import warnings
import time
def remove_formulas_from_excel(file_path, save_path=None):
"""
删除单个Excel文件中的所有公式,保留计算结果
"""
try:
# 加载工作簿
wb = load_workbook(filename=file_path)
# 遍历所有工作表
for sheet_name in wb.sheetnames:
ws = wb[sheet_name]
# 获取最大行和列
max_row = ws.max_row
max_column = ws.max_column
# 遍历所有单元格
for row in range(1, max_row + 1):
for col in range(1, max_column + 1):
cell = ws.cell(row=row, column=col)
# 检查单元格是否有公式
if cell.value is not None and isinstance(cell.value, str) and cell.value.startswith('='):
# 公式单元格,获取其当前显示的值
# 注意:openpyxl不会计算公式,所以我们需要特殊处理
# 方案1:如果文件是.xlsx且有缓存值,尝试获取
if cell.data_type == 'f': # 这是一个公式
# 尝试获取公式的计算结果(如果存在缓存值)
if hasattr(cell, '_value') and cell._value is not None:
cell.value = cell._value
else:
# 如果没有缓存值,保留公式文本或设置为空
# 这里我们选择设置为公式的文本表示(不含等号)
cell.value = str(cell.value)[1:] if len(str(cell.value)) > 1 else ''
else:
# 非公式单元格,保留原值
pass
# 另一种判断方式:检查单元格的is_date属性等
elif cell.is_date:
# 日期格式保持不变
pass
# 确定保存路径
if save_path is None:
save_path = file_path # 覆盖原文件
# 保存工作簿
wb.save(save_path)
print(f"✓ 已处理: {file_path}")
return True
except Exception as e:
print(f"✗ 处理失败 {file_path}: {str(e)}")
return False
def batch_remove_formulas(folder_path, output_folder=None, file_pattern="*.xlsx"):
"""
批量处理文件夹中的Excel文件
"""
# 创建输出文件夹
if output_folder:
os.makedirs(output_folder, exist_ok=True)
# 获取所有Excel文件
search_pattern = os.path.join(folder_path, file_pattern)
excel_files = glob.glob(search_pattern)
# 添加其他格式
for ext in ['*.xls', '*.xlsm']:
excel_files.extend(glob.glob(os.path.join(folder_path, ext)))
if not excel_files:
print(f"在 {folder_path} 中未找到Excel文件")
return
print(f"找到 {len(excel_files)} 个Excel文件")
# 处理每个文件
success_count = 0
for file_path in excel_files:
try:
# 确定输出路径
if output_folder:
filename = os.path.basename(file_path)
save_path = os.path.join(output_folder, filename)
else:
save_path = file_path # 覆盖原文件
# 处理文件
if remove_formulas_from_excel(file_path, save_path):
success_count += 1
except Exception as e:
print(f"✗ 批量处理失败 {file_path}: {str(e)}")
print(f"\n处理完成!成功处理 {success_count}/{len(excel_files)} 个文件")
def remove_formulas_using_data_only_mode(folder_path, output_folder):
"""
使用data_only模式读取文件,这样公式会自动转换为值
这种方法更可靠,但需要读取文件两次
"""
excel_files = []
for ext in ['*.xlsx', '*.xlsm', '*.xls']:
excel_files.extend(glob.glob(os.path.join(folder_path, ext)))
for file_path in excel_files:
try:
# 使用data_only模式打开文件,这样公式会被读取为计算结果
wb = load_workbook(filename=file_path, data_only=True)
# 保存到新文件
filename = os.path.basename(file_path)
save_path = os.path.join(output_folder, filename)
wb.save(save_path)
print(f"✓ 已处理: {file_path}")
except Exception as e:
print(f"✗ 处理失败 {file_path}: {str(e)}")
# 使用示例
if __name__ == "__main__":
# 示例1:直接覆盖原文件
# batch_remove_formulas("C:/ExcelFiles", output_folder=None)
# 示例2:保存到新文件夹
batch_remove_formulas(
folder_path="C:/ExcelFiles",
output_folder="C:/ExcelFiles_NoFormulas",
file_pattern="*.xlsx"
)