批量提取PDF扫描件(图片版PDF)中指定区域的内容
做过数据录入工作的人应该都有体会,很多时候我们拿到的PDF并不是可以直接复制文字的那种,而是扫描生成的图片版PDF。这类文件看着像普通文档,但实际上里面的内容都是"死"的——选不了、复制不了、搜索不了。如果想要将里面的内容提取出来,就只能手工一个个的敲。少量的几份花点时间还能搞定,但是文件很多的时候,光靠人工一份一份去看、去敲就不太现实了。
举几个我自己和同事经常碰到的场景吧。做财务的同事每个月要处理几百张供应商发过来的扫描版发票,需要把发票号、金额、开票日期这些字段一个个手动录到Excel里;做物流的要从大量运单扫描件里提取收件人信息和单号;还有做合同管理的,几百份老合同都是当年扫描存档的,现在要统一整理合同编号、签约日期和甲方名称。这些场景有一个共同点:每份文件要提取的信息位置其实都差不多,但就是没法批量搞定。
很多人第一反应是用OCR工具,装个软件识别一下就行了。但实际用过就知道,大部分OCR工具要么只能整页识别,输出一大堆文字还得自己再去里面找需要的字段;要么不支持批量处理,一份一份打开、识别、导出,效率并没有提高多少。更别说有些工具识别准确率一般,碰到盖了章的区域或者表格线密集的地方,识别出来的内容错漏百出,还得人工核对。说白了,真正的需求不是"把整页文字识别出来",而是"从每份文件的固定位置,精准提取我要的那几个字段,然后批量导出"。
批量提取PDF扫描件中指定区域的内容效果预览
提取前
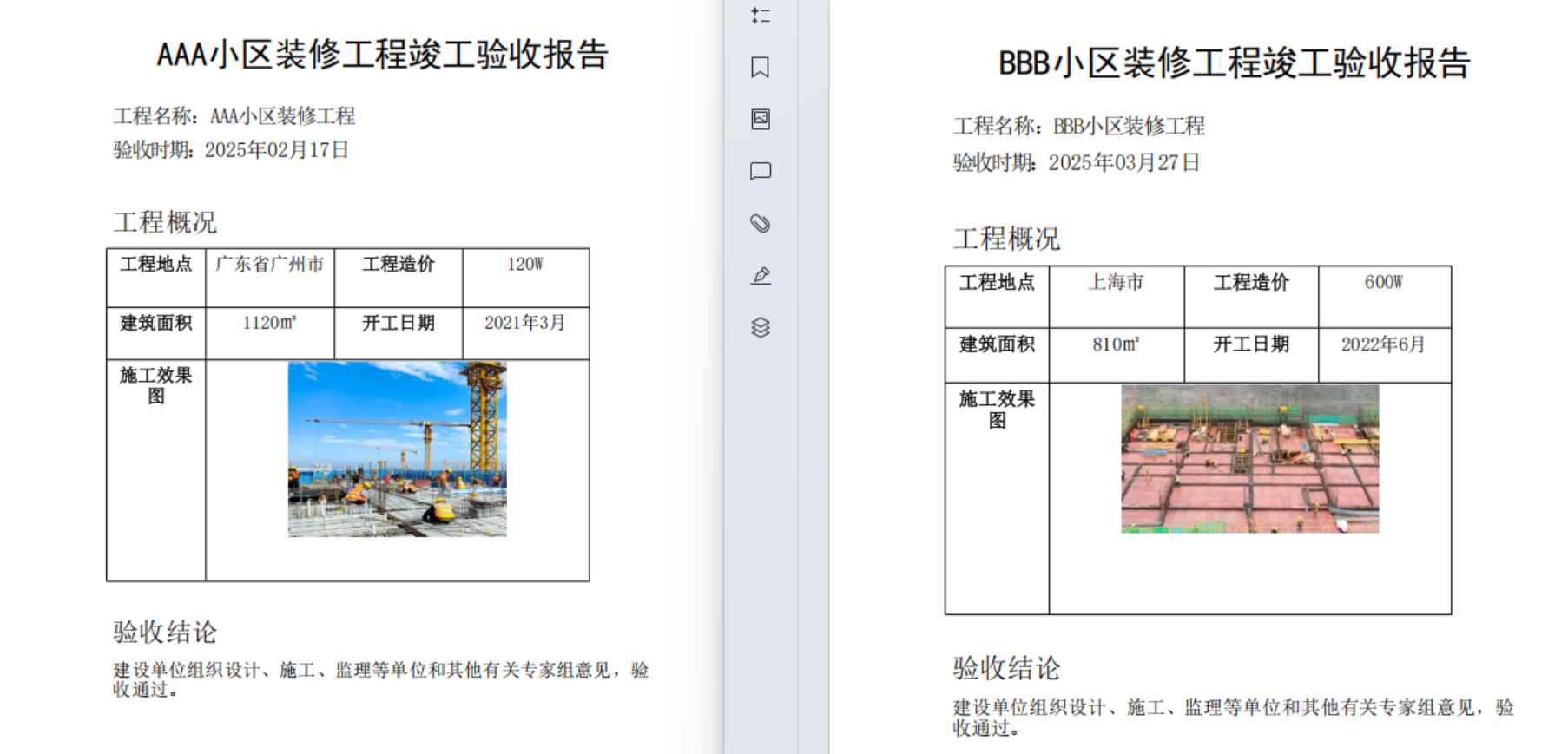
处理前,文件夹中有多个 PDF 文档

这些 PDF 文档中的内容都是相同的结构,只是内容不相同,并且这些pdf文件中的内容是一张图片,不可以复制
提取后
提取后,每个 PDF 文档中都是一条单独的数据,每条数据对应一个 PDF 文件内容。

操作步骤
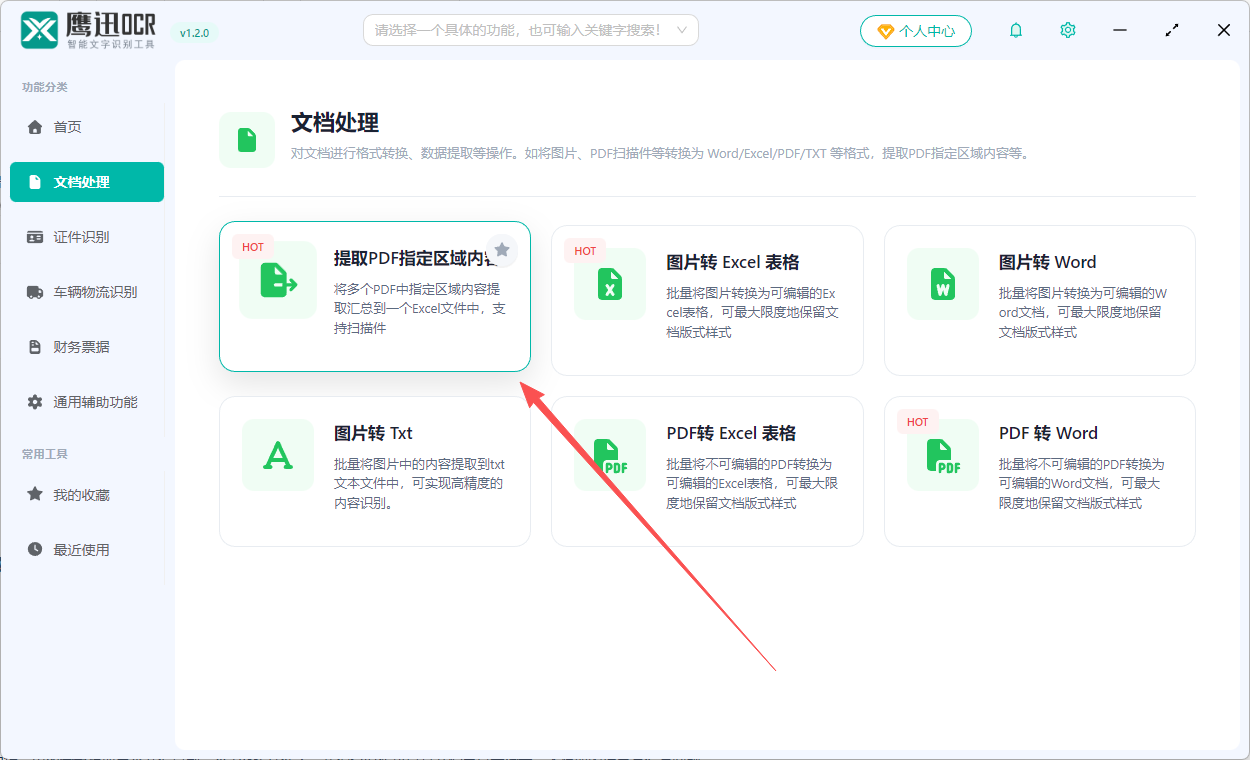
1、打开「鹰迅OCR」,左侧选择「文档处理」,右侧选择「提取PDF指定区域内容」的功能。
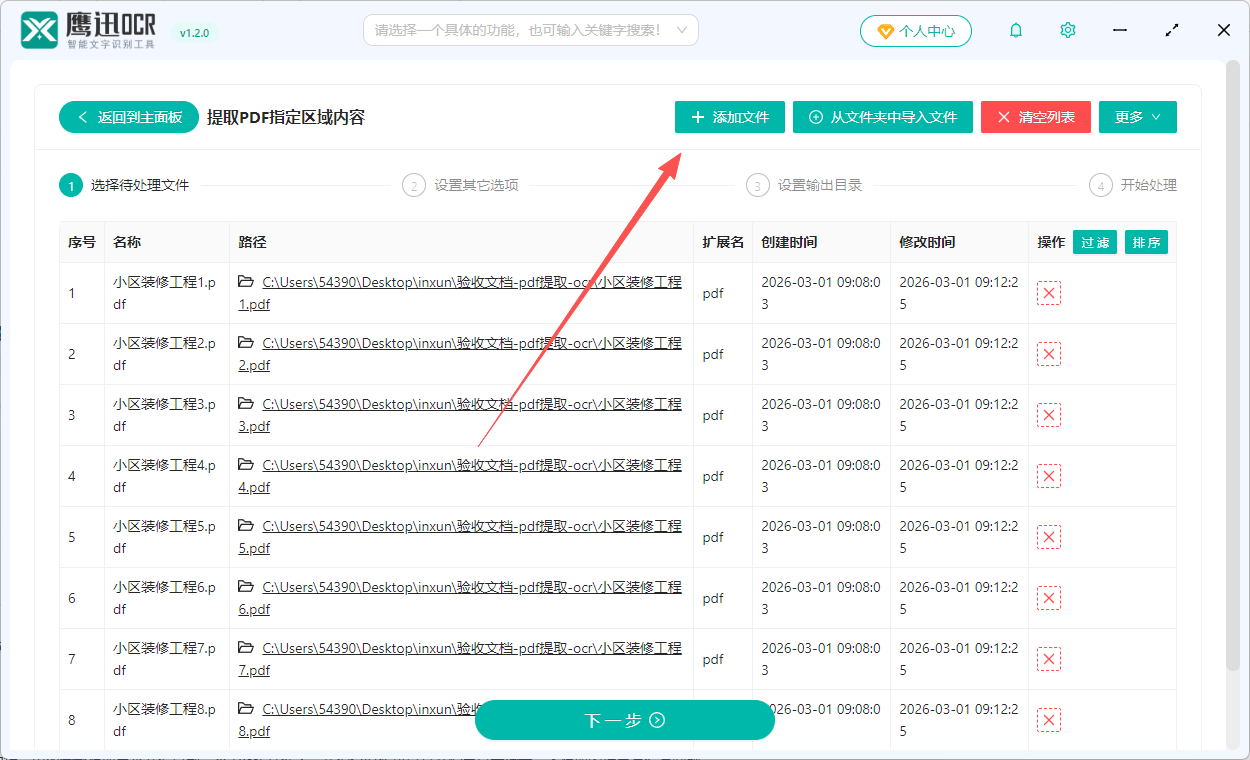
2、选择需要进行数据提取的 PDF 文件,不管是文字版 pdf 还是 pdf 扫描件,这里都支持提取。
3、设置提取的规则。
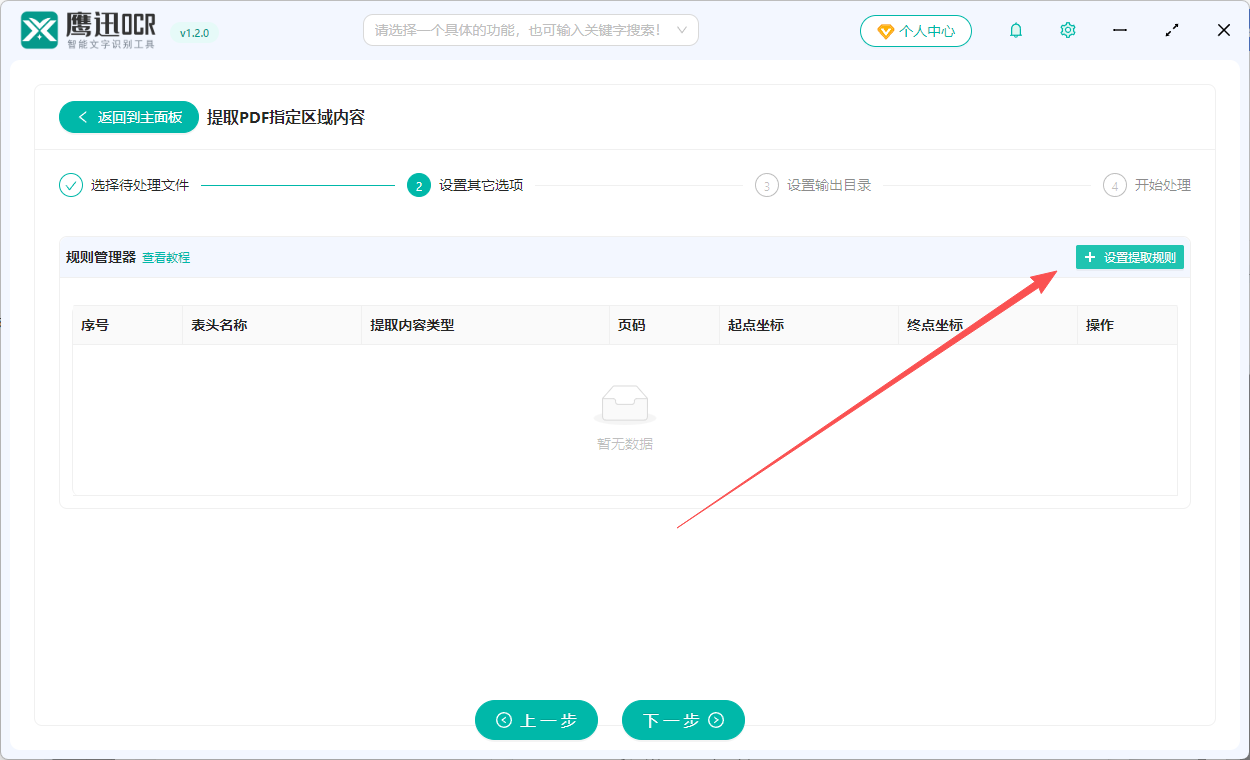
刚进入页面时,是没有任何提取规则的,我们可以点击「设置提取规则」按钮会打开弹窗进行规则的设置。
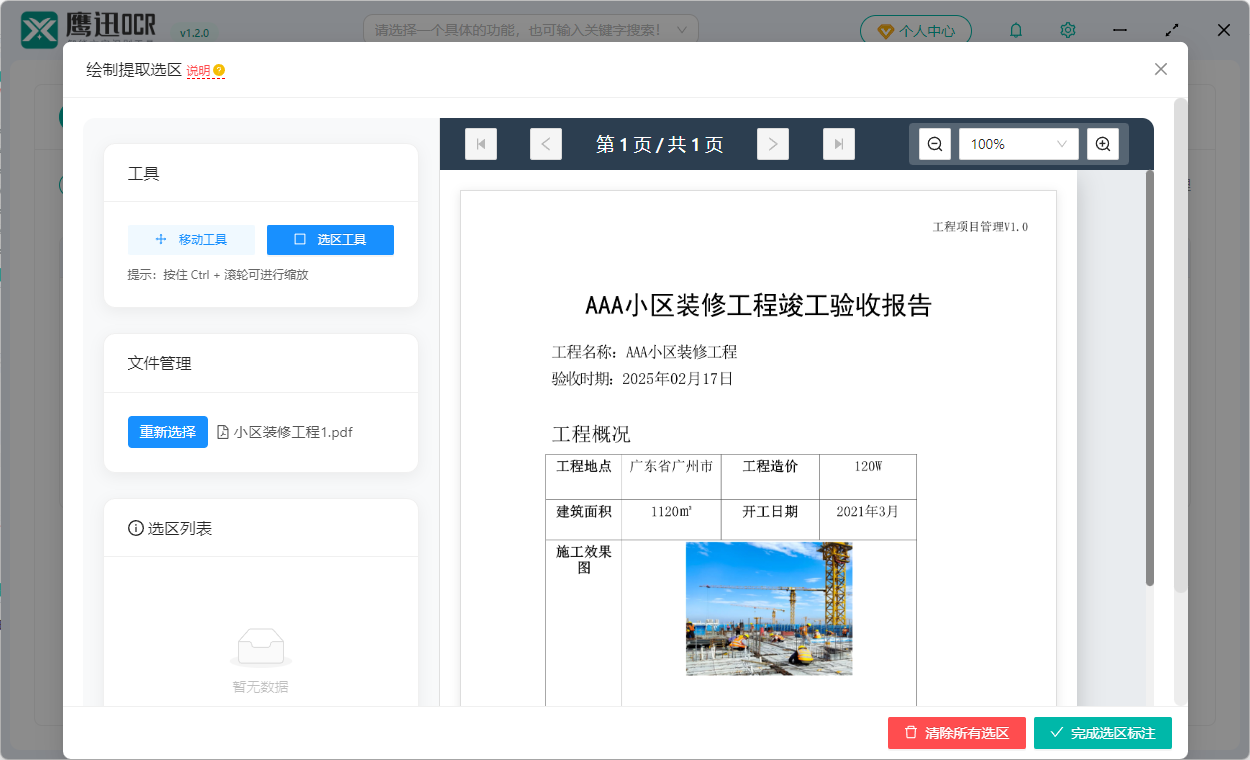
- 在规则设置的界面中,默认会加载我们选择文件列表中的第一个 PDF 文档,当然也可以点击「重新选择」按钮选择其它的 PDF 文档。
- 在 PDF 预览区域,我们可以在需要提取的内容部分绘制选区,绘制的选区有起始坐标,最终软件就会根据这里绘制的选区坐标对每一个 PDF 文件进行内容的提取。
- 我们每绘制一个选区,都会弹窗需要输入「表头名称」,这也就是我们最终提取到 Excel 中显示的表头名称。还会需要我们选择提取的内容内容,目前支持文本和图片两种类型。
- 按住 Ctrl + 滚轮,在 PDF 预览区域内可以进行缩放,方便我们绘制更精准的选区。
- 当 PDF 文件有多页时,我们可以进行页面的切换,可以指定提取内容所在的页面。
选区绘制后,效果如下。
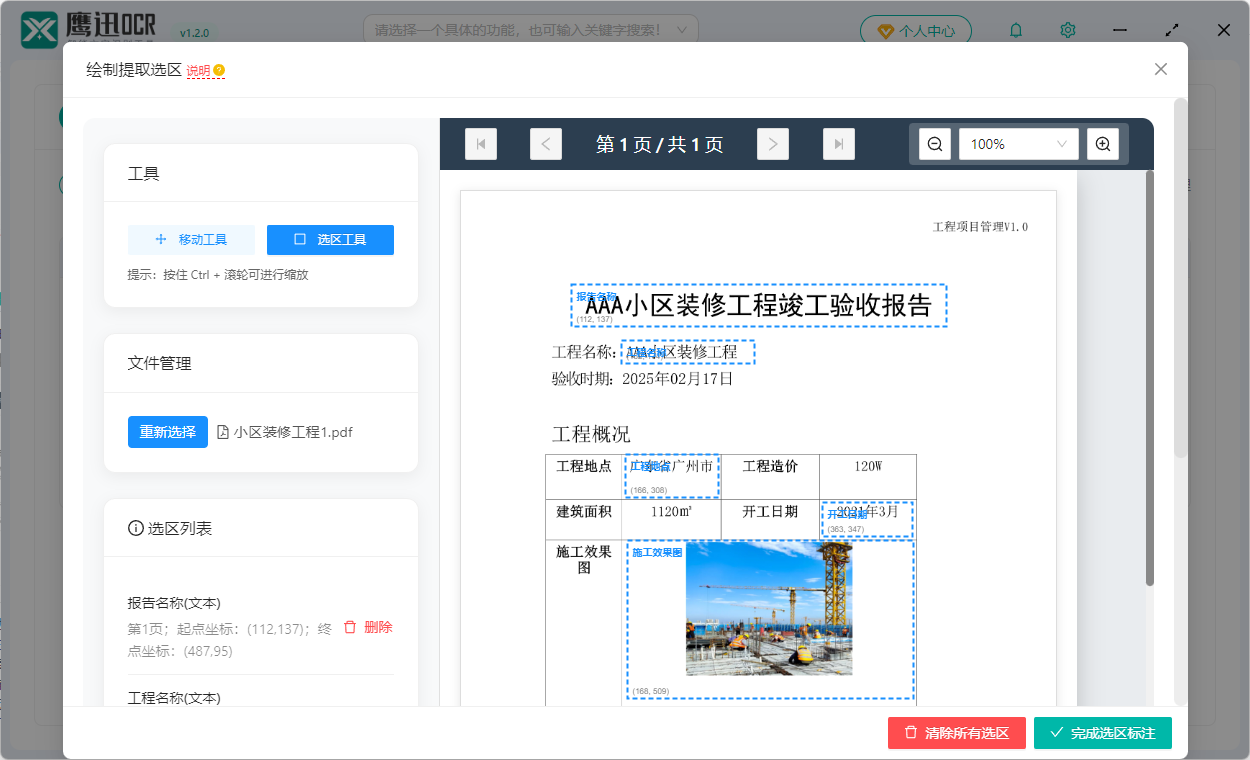
绘制好选区后,我们点击右下角的「完成选区标注」按钮即可。
4、设置输出目录。
4、PDF 指定区域内容提取完成。
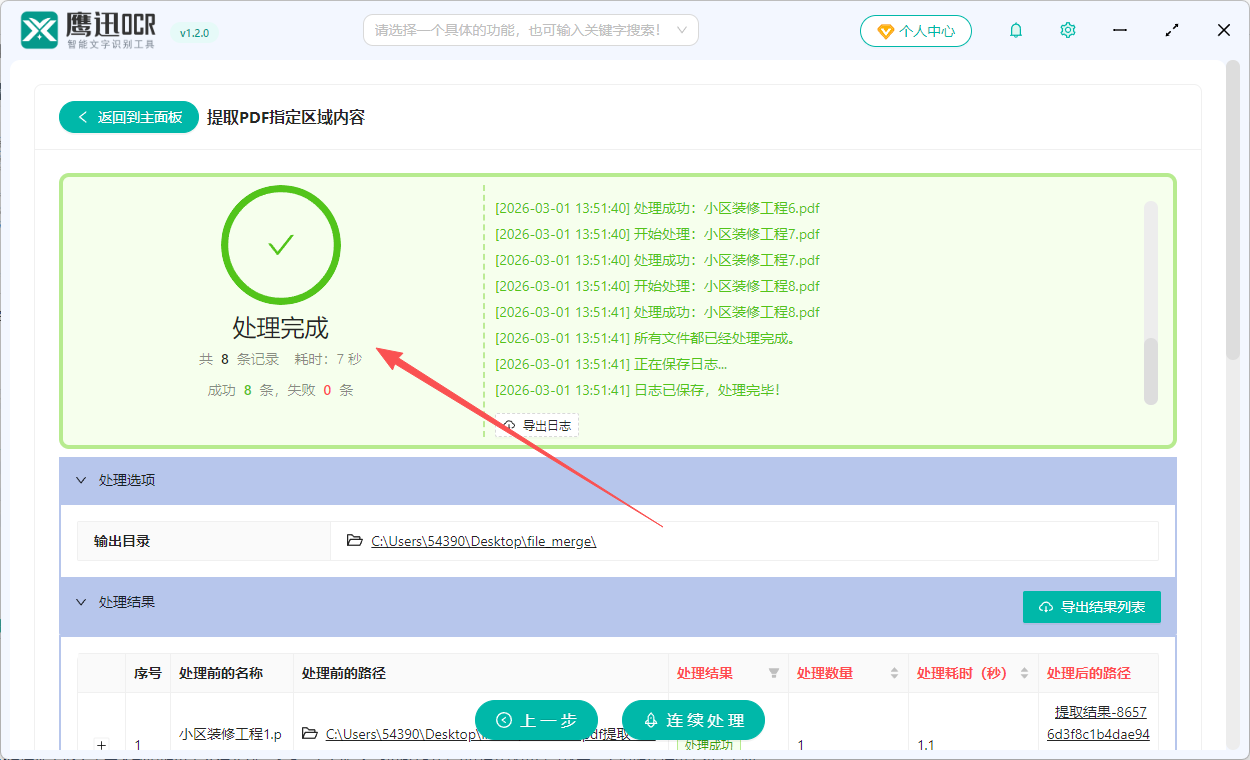
就这样简单的几步,我们就将多个pdf扫描件中指定内容全部提取出来并汇总到一个 Excel 文件了。我们这时候可以打开输出目录检查一下提取的结果有没有问题。
整个操作下来,最直观的感受就是省时省力。以前处理200份扫描件,手动录入怎么也得大半天,现在框选好区域,批量跑一遍,几分钟就能拿到结果,直接导出成Excel表格。后面不管来多少份同类型的文件,都是一键处理的事。对于那些每天要跟大量扫描件打交道的岗位来说,这种批量、定点提取的方式,确实从根本上解决了重复劳动的问题,把时间留给更有价值的工作。